Airgapped systems are often treated as static, permanent, and immovable.
They’re offline.
They’re hardened.
They’re not changing anytime soon.
Until they do.
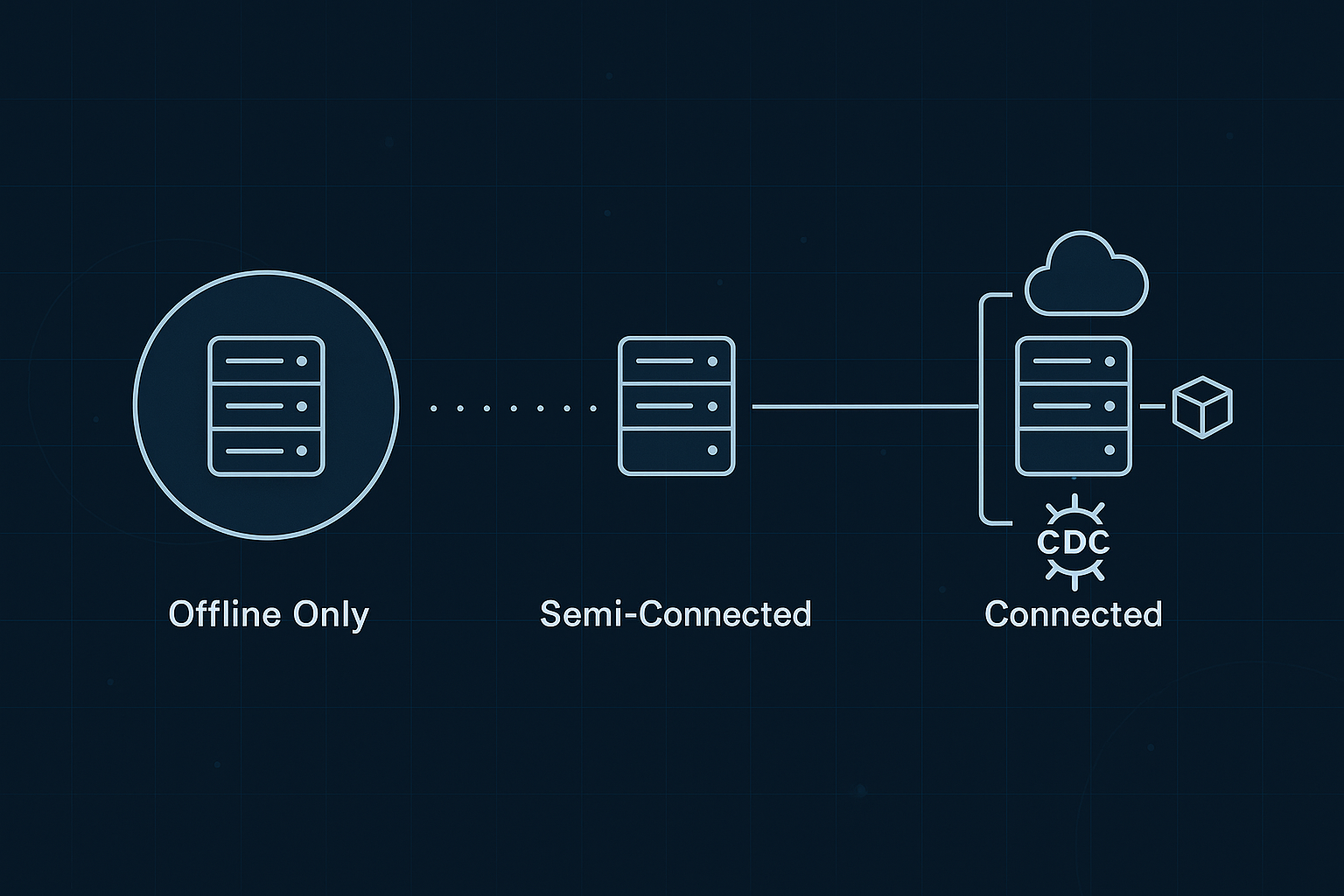
More and more, we’re seeing environments that start as fully disconnected gradually gain controlled access to the outside world. A system that began life on a USB stick might later receive daily updates over a satellite link. A once fully isolated deployment might eventually support secure relay syncs or controlled egress through a policy gateway.
If you’ve heard the word airgap and thought “oh, that’s just for submarines,” you’re not wrong — but you’re also missing the bigger picture.
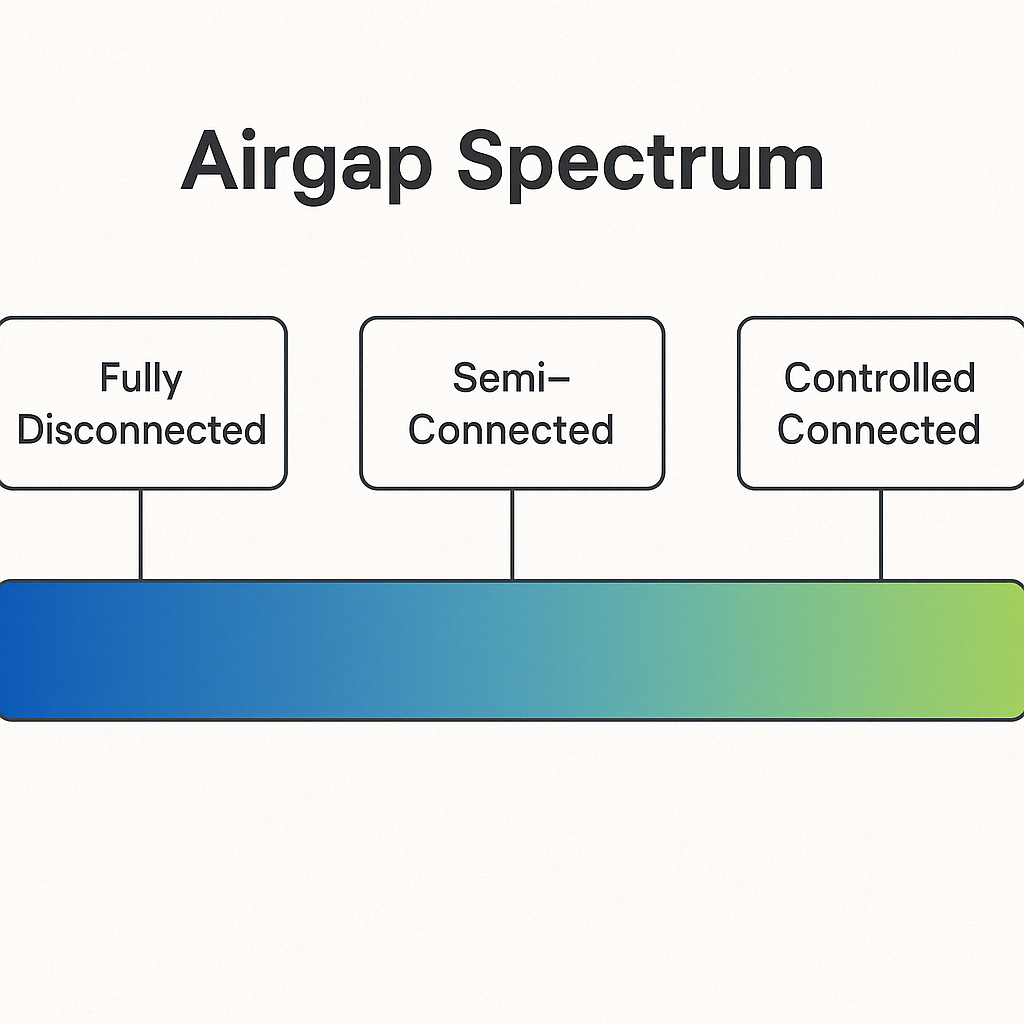
Airgaps aren’t binary. It’s not either full-internet or total-isolation. This may seem counterintuitive to some… Airgap feels pretty binary.
There’s a spectrum here — maybe not all functions or capabilities within your system are airgap-dendent. Understanding where your system lives on this spectrum is key to building something that doesn’t fall over the second a network hiccups.
If you’ve ever worked in a disconnected environment - or even just a flaky one - you probably understand.
That feeling when something fails not because your code is broken, but because your tooling made an assumption about connectivity.
A tiny one.
A quiet one.
But critical enough to tank the whole operation.
Let’s talk more about that.
Cloud native assumes the internet will always be there
Most modern platforms lean hard on SaaS services, cloud APIs, dynamic registries, and live secrets. This makes things feel seamless - until the network drops, your git platform goes sideways, or DNS just stops cooperating.
Welcome to the first post in my Cloud Native Airgap Fundamentals series.
If you’re reading this, odds are you’ve been burned by a dependency you didn’t even know you had.
A Helm chart that fetched something from an external source or had sub-charts.
A Kubernetes deployment that pulled an image at runtime. (IE Operator)
A pipeline that silently relied on a cloud API to fetch secrets.
A security application that requires centralized data retrieval for operation.
If you’re anything like me - you often prepare for the worst any time it’s critically important to execute.
Build - Practice - Repeat until it’s muscle memory.
Once that is settled - we start thinking about contingencies. Will I be on Hotel Wifi? What will happen to my bandwidth if I try pulling container images to a local cluster? Will it wipe out my audio/video?
Whether it’s an important mission hero or conference demonstration - how do you reduce potential room for error?
Events occur, Priorities shift, adaptation is required.
The last year has been a consistent roller coaster. I’ve always been on the edge of what defines security controls and how we architect systems to meet and exceed the requirements. My knowledge of compliance was sufficient enough to collaborate with others on answering the required controls and moving on with development efforts.
The thing is we knew that better existed - or that it should. The processes were frustrating, time is expensive, and generally the fidelity of the data didn’t meet the same fidelity of the other artifacts we were producing.
Warning - this is a large amount of text highlighting general strategy for my time at this conference. What I deem as valuable may not work for others with separate strategies. See the TLDR of each day if interested in the general overview.
KubeCon has wrapped up and with it I can definitively say that it was the most productive and impactful event in all of my previous KubeCon attendances. I went into this event with a strategy - which included observations and exploration as well as targeted tasks.
It’s no secret - and likely I am a broken record at this point - that homelabbing is not only a hobby of mine, but also a great activity for learning.
The experiments I have ran from my own hardware have informed me in ways where I could participate in discussions and architectural decisions in ways that provided value to myself and others. It is still an activity that I work to establish as a habit in some way/shape/form throughout my schedule.
In a week of the news around xz utils backdoor vulnerabilitity, it provides a reminder that there are systems that we need to remain vigilant in monitoring.
I’m a believer that one of our most vulnerable assets is our developer environments. We conduct tons of experimentation and use them to drive upgrades to downstream systems.
How are we keeping track of what is installed and the versions etc? seems like a solved problem - but I can guarantee that even big enterprise still remains vulnerable - more so in the age of containers.
If there is one value that I believe has contributed to the most meaningful time spent - in work and out - it’s the guiding principle that How you do anything is how you do everything. I don’t know where I originally heard it - but it immediately resonated as a truth with me.
Break it down
Hear me out - from the task that are very important and require intense focus - to the menial, routine tasks that require your attention in order to get them done - how you approach doing them is often consistent over time. Meaning that your system for approaching and solving any problem at hand is a byproduct of your systems. As James Clear puts it, “You do not rise to the level of your goals. You fall to the level of your systems”.