Especially when the data is fun to aggregate and process. Finally some code!
I’ve been using a free Strava account for years now. It tracks my workouts and gives me some high-level information to share with friends and followers.
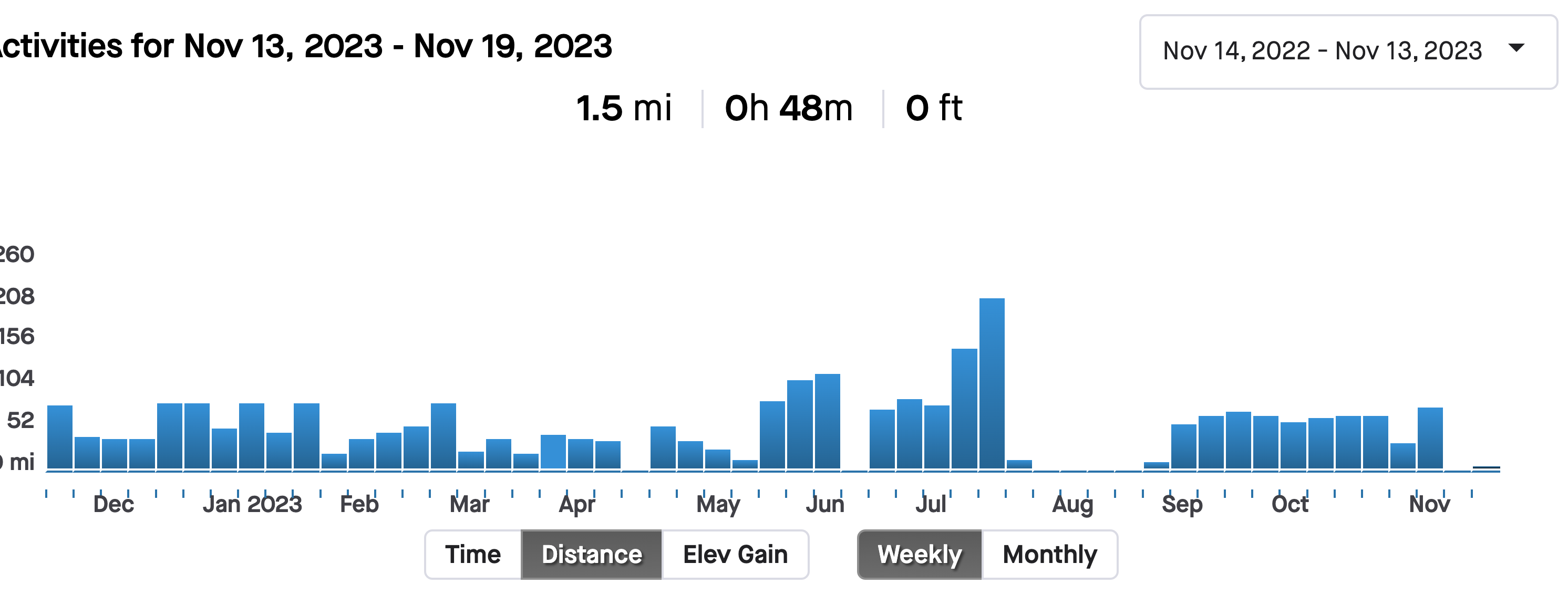
Desk Treadmill data
For each workout that I have been recording with the hardware from the previous post, I’ve specifically been naming them “Desk Treadmill” such that I could easily aggregate them in the future.
I will always admit that I love everything that is working for a fully remote company. I’ve battle tested the 2+ hr commute daily for longer than I cared to admit, and that time feels like a huge part of my life has been wasted. Working remotely has offered me time to focus on the things that matter, when they matter.
Focusing on work and the tasks at hand - with zero interruption - while also being able to inject random bouts of family time throughout the day that I would have otherwise not had the ability to do. This is a huge part of my life. Snack time with my daughter when I’ve been banging my head against the wall for hours.
Knowing that I wanted to have data about my use of the treadmill to backup my claims about how I perceived using it day-to-day was one of my goals. Another being, that as a cyclist and general Strava user, I knew that I already had the platform available for storing my data as well as had seen API access available (but had never used it before).
Now it was a matter of piecing the pipeline together.
In the previous installment of the ongoing desk treadmill experiment (linked below), I mentioned that the circumstances of the treadmill I use today was probably not what the sane person would have done.
Rather I honestly had no intention of starting this experiment this year. Instead this experiment was a result of being in the right place at the right time and keeping the spirit of tinkering alive.
Right Place
With my “Always Tinkering” mindset, I was browsing the marketplace one weekend and decided to browse the offerings for treadmills. More of a fluke than anything I found a listing for an Under Desk Treadmill at the price of $0 with a description that it turns on but displays an error.
KubeCon and CloudNativeCon North America 2023 is fast approaching. It is without contest my favorite event of the year.
What I wanted to do was outline some tips for everyone - from first time attendees to experienced attendees - for what I believe contributes to a great event.
Situational Awareness
First an foremost do some logistical planning:
How far are you from the venue?
What will you need to bring based upon that?
What all do you have have planned that may change what you need?
Rarely has the venue ever been hot - and we’re talking November in Chicago so a warming layer may not be a bad idea.
When I set out to created this blog, as noted in my Blogging the hard way article, I had a couple key objectives that I wanted to pursue:
Reproducible and static
Meaning highly portable
Minimal configuration required
Markdown content and generate
And most importantly - Open - as in anyone can look at the repository and see every single detail that makes this site run. If I inspire even one person to have some fun exploring Hugo and the adventure that is serving content to the world from the comfort of their own home - then I’d call it a success.
For those are are emerging into the AI space later than others - like myself - I found the prospects and Retrieval-Augmented Generation (RAG) to be a great capability. RAG is not new but it connects from of the underlying AI magic to decision making that makes sense.
The missing piece? Context/Background.
Retrieval-augmented generation in Language Models (LLMs) is a framework that combines the capabilities of both retrieval models and generative models to improve the quality and relevance of generated text. This approach aims to enhance the generation process by incorporating information retrieved from external sources during text generation.
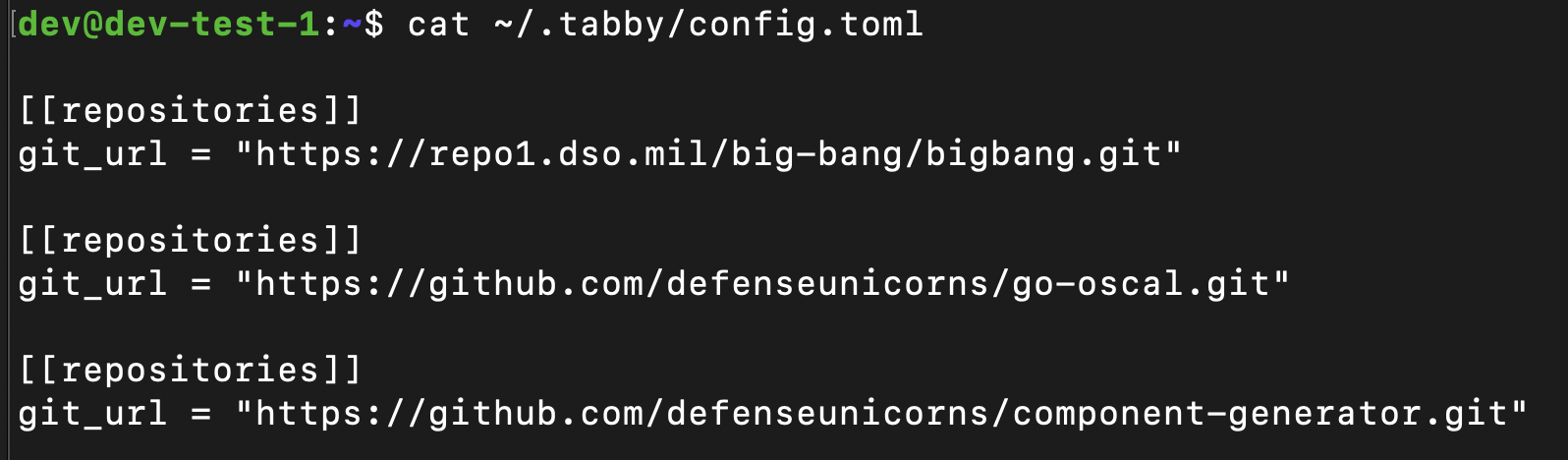
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot.
HomeLab
For those who haven’t read my previous review of FauxPilot, I have been experimenting with Open Source CodeGen AI for the last few months. Using an old desktop I convert to Proxmox, I dedicated my RTX 2080 to an Ubuntu VM that is my current test-bed for AI code generation tooling.
For quite some time now I’ve helped build platforms and the focus has always been to deliver value to the end user first and foremost. What capabilities would we enable and how great the future would be amiright?
Early in this learning process was the role that dependencies played. The more you layered dependencies on top of one another - the greater the mountain of said dependencies grew from something maintainable to an overgrown monstrosity that threatened to break at any run of CI you introduced.
This is part one of multiple blogs posts about my standing desk and treadmill combo that I have planned for the forseeable future. Reason being the impact on my physical and mental wellbeing since i’ve began incorporating it into my daily working life.
In order to describe where I am at - I need to tell you about where I’ve been. Bear with me for the start of this article as it gets more interesting. If you want the TLDR - scroll to the results/conclusion below.